
Have you ever gone out for a tour, and found yourself in a situation where you need a guide to visit important places. Then, the search engine crawler also needs one guide book to crawl your website and here it comes the robots.txt file which guides the search engine crawler which page to crawl and which page to not.
What is robots.txt?
Robots.txt is a file which the site owner creates in order to tell search engine spider which url to crawl and which url not to crawl. It is also known as the robots exclusion standard. This file is generally placed in the root directory of the website.
You can simply type https://yourdomainname.com/robots.txt to get the robots.txt file.
All the major search engines out there follow this robots exclusion standard.
Why do we use robots.txt file?
There is a very need for the robots.txt file for most of the websites on the internet. If you don’t have one the spider bot will simply crawl the website and index all the pages.
So, why do we need that robots.txt file after all the crawler will crawl the site any way, when should you use a robots.txt file.
One will need the robots.txt file for one of the three reason
Keeping some folder or page private
There must be some pages on your site that you might not want to be indexed. Such as the admin login page. You might not want any random user landing on the login page and also it will be a security threat for your website itself.
For that, you can use robots.txt protocol, so that the page might not get indexed.
More pages need to indexed as quickly as possible
If you have a big website or ecommerce website having thousands of pages and you want to index all these pages as quickly as possible. Then you need to optimize the crawl budget. The best way to do that is by instructing the crawler not to index the unimportant pages, media files, videos, etc.
If you are a wordpress user then you might find some pages are automatically created as tags which may cause the duplicate contain issue. For that case also you can use robots.txt file not to index these pages.
Decreases the server overload possibility
If some users got into unimportant pages which they are not in need of and your site always get high traffic , then the server overloading will occur, which might crash your site. And hence affects the user experience.
Cons of robots.txt files
It will still index some pages
The crawler will still index some pages that you have instructed in robots.txt file not to index. This happens if your url is also placed in other websites also.
Different crawler will interpret the rules differently
Though the robots.txt file provides the similar instructions to the web crawler, but some search engines spider might interpret the instruction differently.
You can check the misleading instructions by the crawler by simply checking the google search console page indexation data.
Some symbols to know before creating Robots.txt file
user-agent: This specifies the search engine crawlers, who will follow the rule.
‘*’asterisk: This is an universal sign, meaning all search engine crawlers.
disallow: This instruct search engine crawler not to crawl
allow: This instructs search engine crawlers to crawl. This is used to nullify the disallow instruction to crawl the sub-directory in the directory.
Sitemaps: It contains all the urls that you want to index. And the crawler will follow the sitemaps for indexation.
How to create robots.txt?
Before creating any robots.txt file first check whether your website has a txt file or not.
You can create the txt file both by using tools or by manually.
There are many online tools that are present which will help you in creating the robots.txt file but they only create a simple instruction. You don’t have freedom to customize as you want.
How to create robots.txt file manually?
The best way to create it is by doing it manually. For creating it you need a text editor like a notepad.
So, login to the cpanel and open the file manager.

Open the public_html folder and find the robots.txt file. If the file exists the edit the file and if not then create a new one.
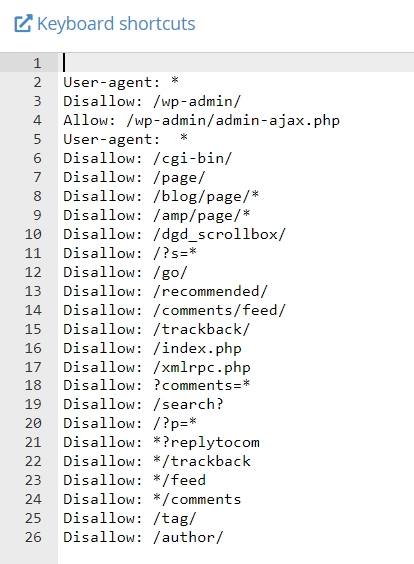
Type the possible instruction which you want the crawler to follow and then save changes.
How to add robots.txt in wordpress?
If you are a wordpress user here, where you can create and add the robots.txt file using some seo plugins like all-in-one seo, yoast seo, rankmath pro.
In this blog we will show you by using rankmath pro.
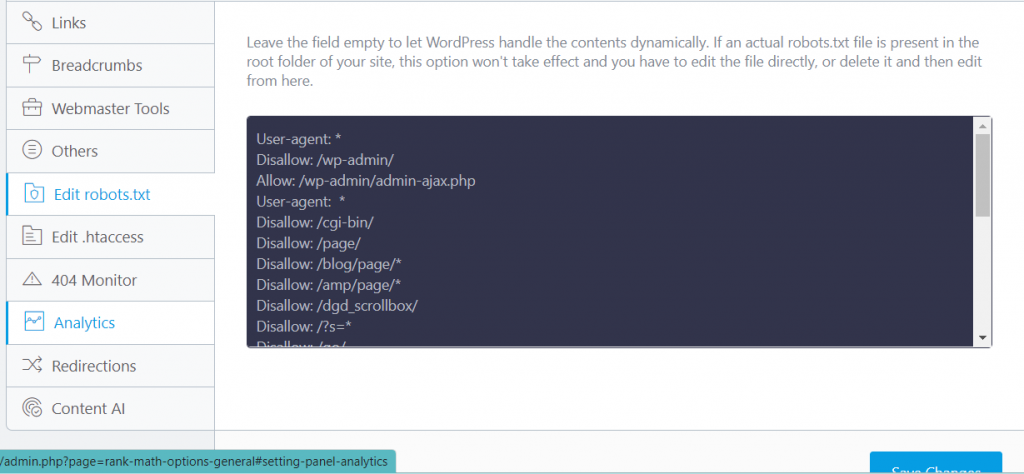
First of all login to the wordpress dashboard select the rankmath icon on the menu and then select the general settings option
Open the option edit robots.txt. Place the instructions and save changes. That’s done.
How to check robots.txt?
You can simply check the robots.txt file in the google search console. And also I am providing the link of robots.txt checker. If you don’t have an account on google search console, then first create it and then check it.
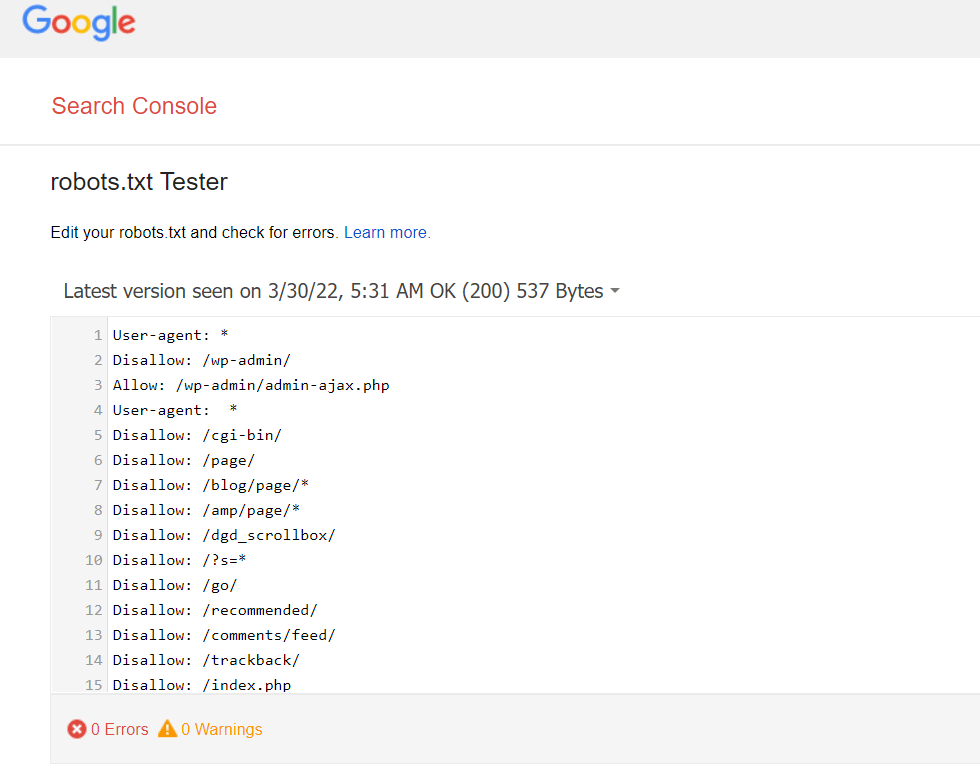
If it shows no error then it’s good to go.
Which on better robots.txt or meta directories
It depends upon the size of the website. If you have a small website then use meta directories instead of robots.txt. But if you have a bigger website go for robots.txt.
What happens if your robots.txt file has some errors?
These mistakes are generally made by beginners. But if it shows an error it means it will not index the page that we want to index. Sometimes, a small error in the robots exclusion protocol may lead to no indexation of the whole website.
What mistake in instruction may lead to blocking of the whole website?
If the robots.txt file give the instruction like
user-agent: *
disallow: /
This discourages the search engine from indexing the site.
For wordpress users make sure you must keep the usage tracking section unchecked. So that the spiders can index the site.
If you need more information about the robots.txt file then make sure to check the google search central blog.
Pingback: Beginner to advanced Guide: basics of technical seo
Pingback: What is canonical issue? Why it is important in seo?